

Analiza nezavisnih komponenti ICA
Analiza nezavisnih komponenti (Independant Component Analsysis) ili ICA je metoda analize koja se u oblasti neuroimidžinga primenjuje na podatke dobiju nakon predobrade. Cilj ICA je dekompozicija multivarijabilnog signala u skup karakteristika koje predstavljaju neku strukturu koja je prisutna u podacima (zvane komponente). Stoga, ICA pretpostavlja da su posmatrani podaci mešavina više osnovnih komponenti koje se ne mogu direktno posmatrati, ali se mogu razdvojiti.
Primer za razumevanje koncepta je boravak u prostoriji i slušanje predavanja; čujemo glas predavača, ali može se čuti i pevanje ptica napolju, lupanje od građevinskih radova u susednoj zgradi, a možda čak i zvukove akvizicije koji dolaze iz MRI skenera u prostoriji ispod. Dakle, signal koji naše uši hvataju je mešavina svih ovih izvora, ali naš mozak je u stanju da ih razdvoji i obrati pažnju na glas predavača.
ICA koristi isti pristup na fMRI podacima u stanju mirovanja i ima za cilj da odvoji BOLD signal (što je mešavina koja se ovde posmatra) u odvojene osnovne komponente. Prema tome, ICA je po definiciji multivariabilni pristup, jer uzima u obzir sve podatke iz svih voksela odjednom da bi pronašao komponente. Kada se primenjuje ICA, svaka rezultujuća komponenta se opisuje kao prostorna mapa (koja odražava gde se u mozgu detektuje određeni deo signala) i vremenska serija (koja opisuje kako se signal razvijao tokom vremena).

ICA posebno traži komponente koje su maksimalno nezavisne jedna od druge. Statistička nezavisnost u suštini znači da ne postoji statistička veza između dve izvedene komponente (tj. nisu u korelaciji i nemaju veze višeg reda). Kada su dva signala statistički nezavisna, ne postoji način da se predvidi signal jednog na osnovu drugog signala.
Ograničenje nezavisnosti mora biti primenjeno na jednu od dimenzija podataka, tako da je u slučaju fMRI analize u stanju mirovanja moguće izabrati ili tražiti signale koji su vremenski nezavisni (temporalna ICA) ili tražiti signale koji su prostorno nezavisni (prostorna ICA). Dok se i prostorna i vremenska ICA primenjuju na fMRI podatke u stanju mirovanja, najčešće usvojeni pristup je prostorna ICA. Razlog je daleko češće imamo mnogo više voksela (do 100.000 za tipične podatke) nego vremenskih tačaka (obično stotine ili u najboljim slučajevima nekoliko hiljada po subjektu).
Grupna-ICA dekompozicija
Pored toga što se ICA može primeniti na podatke jednog subjekta kako bi se identifikovale i uklonile komponente nečistoća signala, ICA se takođe može koristiti na nivou grupe. Tada se koristi da bi se identifikovale velike mreže stanja mirovanja (kao što je default-na mreža ili mreža ,,uobičajenog režima rada”), koristeći stanje mirovanja iz grupe subjekata. Kada se izvodi grupna-ICA, ulazi podaci su predobrađeni i očišćeni BOLD podaci stanja mirovanja svih subjekata.

Kombinovanje fMRI podataka u stanju mirovanja za ICA dekompoziciju na nivou grupe se obično vrši prostornim registrovanjem svih subjekata u standardni prostor, a zatim vremenskim nadovezivanjem registrovanih skupova podataka svih subjekata. To znači da se vremenski serijali vrednosti (voksela) subjekta 2 nadoveže na poslednju vremensku tačku subjekta 1 i tako dalje, efektivno stvarajući jedan zaista dug skup podataka (slika iznad). Povezani skup podataka od svih subjekata se zatim unosi u ICA, a komponente se ekstrahuju koristeći podatke svih subjekata. Rezultat grupne-ICA dekompozicije je jedna prostorna mapa na nivou grupe za svaku komponentu.
Međutim, često je od interesa da se sprovedu statističke analize kako bi se uporedile komponente između grupa ispitanika da bi se postavila pitanja poput: da li postoje promene u mreži ,,podrazumevanog/uobičajenog režima” između pacijenata koji pate od depresije i zdravih kontrolnih subjekata? Da bi se odgovorilo na ovu vrstu pitanja potrebna je dalja analiza kako bi se izračunale mape specifične za subjekte koje se mogu uporediti, a uobičajeni pristup za ovo je dualna regresije.
Mapiranje nervnih mreža dualnom regresijom
Da bi se statistički uporedile ICA komponente i otkrile razlike u mrežama između individual ili grupa, neophodno je pribaviti mape komponenti svakog subjekta. Dakle za svaku komponentu, treba pribaviti jednu mapu po subjektu, koja opisuje tu komponentu kod tog subjekta (slika). Pri tome, morali bi izbeći problem korespodencije; npr. jedna komponenta kod jednog subjekta može izgledati kao dve odvojene komponente kod drugog. Zbog toga postoji veliki rizik da se na kraju upoređuju komponente koje nisu dobro uparene.
Stoga je praktičnije rešenje da se prvo izvrši grupna ICA analiza kako bi se osiguralo da su komponente iste u svim subjektima, a zatim mapirati ove grupne komponente nazad na pojedinačne subjekte (SLIKA!):
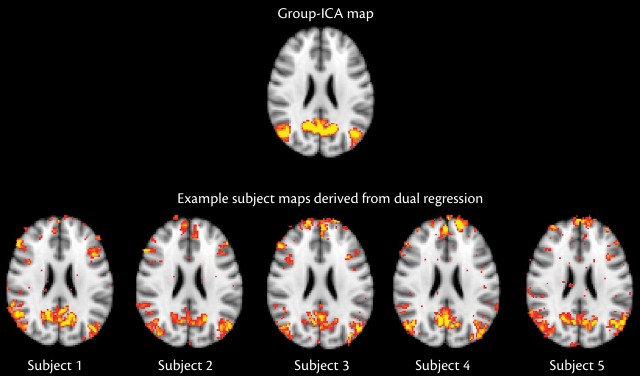
Jedan od uobičajenih pristupa za dobijanje i upoređivanje mapa je dualna regresija. Kao što naziv govori, dualna regresija uključuje dve faze, od kojih su obe analize višestruke regresije. Ideja iza dualne regresije je da se koriste grupne-ICA mape kao šablonski model ukupne mrežne strukture unutar svakog subjekta i da se pronađu mape subjekta koje najbolje odgovaraju ovom modelu.

Faza 2 uključuje drugu analizu višestruke regresije, gde se vremenski regresori dobijeni iz faze 1 (nezavisne varijable) regresiraju u odnosu na predobrađene BOLD podatke istog subjekta (zavisna varijabla). Rezultat faze 2 dualne regresije je skup mapa (po jedna za svaku originalnu ICA komponentu na nivou grupe) koje opisuju strukturu mreže zasnovanu samo na podacima tog subjekta. Mape subjekta mogu da sadrže ili procene parametara (beta vrednosti) ili Z-statistiku (koje su normalizovane bukom unutar subjekta) na svakom vokselu. Iako se bilo koji od ovih tipova mapa može koristiti za dalju analizu na nivou grupe, najčešće se koriste beta mape.

Konkretan primer kako izgleda dualna regresija funkcionalne magnetne rezonance stanja mirovanja jednog pacijenta

Koje grupne mape koristiti za dualno regresiju?
Do sada se pretpostavljalo da koristimo ICA mape na nivou grupe (koje su procenjene korišćenjem podataka svih subjekata) kao ulaz za dualnu regresiju. Međutim, sama procedura dualne regresije je veoma generička i moguće je uneti bilo koji skup mapa. Tri najčešća inputa za analizu dualne regresije su:
- Grupne-ICA mape zasnovane na subjektima iz istog skupa podataka.
- Šablone mapa često upakovane u atlase, koje su dobijene iz prethodnih studija (neki setovi mapa, tj. atlasa, se mogu besplatno preuzeti).
- Mape koje su dobijene iz grupne-ICA dekompozicije izvedene na skupu nezavisnih subjekata (od kojih nijedan nije uključen u naknadnu analizu dualne regresije i analize na nivou grupe).
Postoje prednosti i nedostaci za svaki, ali korišćenje šablonskih mapa može biti najpraktičnije. Prednost ovog pristupa je što osigurava da su mreže podeljene na način koji je u skladu sa literaturom i omogućava lako poređenje između studija. Štaviše, u slučaju grupa različitih veličina, upotreba šablona može pomoći da se izbegnu problemi pristrasnosti i složenosti u tumačenju nalaza.
Međutim, šablonske mape ne predstavljaju strukturu koja je prisutna u određenom skupu podataka, kao ni grupni-ICA koji se izvodi na istim podacima i sve komponente buke prisutne na nivou grupe (koje su specifične za studiju) nisu predstavljene šablonskim mapama. Štaviše, neke grupne razlike mogu se otkriti samo pomoću mapa koje bolje predstavljaju strukturu u određenom skupu podataka, pa stoga mogu biti propuštene kada se koriste šablonske mape.
 Treća opcija je korišćenje grupnih ICA mapa koje su dobijene od grupe subjekata koji su nezavisni od subjekata koji se koriste za naknadne analize dualne regresije i poređenja grupa. Na primer, ukoliko imamo pristup ranijoj studiji koju je sprovela ista laboratorija i od ovih subjekata je moguće dobiti grupne ICA mape koje se mogu koristiti u novijoj studiji. Ovaj pristup je sličan korišćenju šablonskih mapa, ali može imati koristi od činjenice da može postojati bolja podudarnost između podataka koji vode grupu-ICA i podataka koji se koriste za naknadnu analizu dualne regresije.
Treća opcija je korišćenje grupnih ICA mapa koje su dobijene od grupe subjekata koji su nezavisni od subjekata koji se koriste za naknadne analize dualne regresije i poređenja grupa. Na primer, ukoliko imamo pristup ranijoj studiji koju je sprovela ista laboratorija i od ovih subjekata je moguće dobiti grupne ICA mape koje se mogu koristiti u novijoj studiji. Ovaj pristup je sličan korišćenju šablonskih mapa, ali može imati koristi od činjenice da može postojati bolja podudarnost između podataka koji vode grupu-ICA i podataka koji se koriste za naknadnu analizu dualne regresije.
Međutim, mape dobijene od druge grupe subjekata još uvek ne predstavljaju u potpunosti strukturu prisutnu u subjektima od interesa, a mape mogu biti relativno ,,nečiste” ako je broj subjekata koji se koriste za grupni-ICA mali. Za ovu opciju, veoma je važno uveriti se da nijedan od subjekata uključenih u grupni-ICA nije takođe deo narednih grupnih poređenja.
Ukratko, pristup dualne regresije je fleksibilan i postoji više različitih načina za dobijanje grupnih mapa koje se mogu uključiti u analizu dualne regresije. Odluka, koja opcija je najbolja za studiju zavisi od istraživačkog pitanja i eksperimentalnih grupa.
Постави коментар
0Коментари